Je vous propose aujourd’hui un détour par les coulisses d’un développement technique : une courte recherche menée à l’occasion de l’écriture d’un plugin Joomla, dont l’objectif est clair — extraire, depuis un fichier PDF, l’ensemble des métadonnées qu’il contient.
Explorer les entrailles d’un PDF
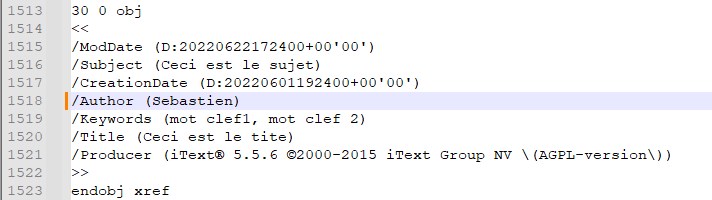
À première vue, la tâche peut sembler anodine. Pourtant, elle suppose de comprendre comment les métadonnées sont intégrées dans un fichier PDF et, surtout, comment les récupérer sans recourir à une bibliothèque spécialisée.
Le cœur du code repose sur l’utilisation d’expressions rationnelles (regex). Chaque motif permet d’identifier et d’extraire une information précise — auteur, titre, date de création, mots-clés, etc... — puis d’en afficher le résultat. Une approche directe, presque chirurgicale, qui consiste à aller chercher les données à la source.
Une donnée méta, lisible par nature, sans outils de "décodage" complémentaire
Pour bien comprendre la logique de cette démarche, un point essentiel mérite d’être rappelé : une métadonnée doit pouvoir être lue sans qu’un logiciel spécifique soit chargé pour interpréter le fichier.
Autrement dit, ces informations doivent être accessibles en clair dans la structure du document. C’est précisément pour cette raison que l’Explorateur de fichiers de Windows, votre gestionnaire favori sous Linux ou encore le Finder de macOS sont capables d’afficher les propriétés d’un PDF sans ouvrir Adobe Reader ou tout autre logiciel dédié.
Cette caractéristique est fondamentale. Sans elle, les métadonnées seraient inexploitables sans une bibliothèque spécialisée capable de parser le format PDF. Leur accessibilité directe garantit à la fois leur portabilité et leur interopérabilité.
Une base à enrichir
Le code présenté ici s’appuie donc sur une série d’expressions rationnelles ciblées, chacune dédiée à l’extraction d’une information spécifique. L’ensemble constitue une base fonctionnelle, mais perfectible.
Libre à vous de le restructurer sous forme de classe ou de fonctions réutilisables, afin de l’adapter plus finement à votre contexte d’usage. Comme souvent en développement, ce travail se veut autant une démonstration de faisabilité qu’un point de départ pour aller plus loin.
<?php
/**********************************************
* URL REGEX : https://regex101.com/r/mC2acW/1
**********************************************/
$nomFichier = 'PDF.pdf'; //Fichier sans mot de passe
$pdf = file_get_contents($nomFichier);
$Tpdf = file($nomFichier);
/*VERSION DU PDF UTILISE */
echo "Version du pdf : ".substr($Tpdf[0],1)."<br>";
/*Pour chacun des "preg_match_all", le résultat souhaité se trouve à l'adresse [0][1]*/
/*RECHERCHE DE L'AUTEUR DU PDF*/
$re = '/Author \((.*)\)/m';
preg_match_all($re, $pdf, $matches, PREG_SET_ORDER, 0);
echo $matches[0][1]."<br>";
/*RECHERCHE DU SUJET DU PDF*/
$re = '/Subject \((.*)\)/m';
preg_match_all($re, $pdf, $matches, PREG_SET_ORDER, 0);
echo $matches[0][1]."<br>";
/*RECHERCHE DE LA DATE DE DERNIERE creation PDF*/
$re = '/CreationDate \((.*)\)/m';
preg_match_all($re, $pdf, $matches, PREG_SET_ORDER, 0);
echo $matches[0][1]."<br>";
/*RECHERCHE DE LA DATE DE DERNIERE MODIFICATION PDF*/
$re = '/ModDate \((.*)\)/m';
preg_match_all($re, $pdf, $matches, PREG_SET_ORDER, 0);
echo $matches[0][1]."<br>";
/*RECHERCHE DES MOTS CLEFS*/
$re = '/Keywords \((.*)\)/m';
preg_match_all($re, $pdf, $matches, PREG_SET_ORDER, 0);
echo $matches[0][1]."<br>";
/*RECHERCHE DU TITRE DU PDF*/
$re = '/Title \((.*)\)/m';
preg_match_all($re, $pdf, $matches, PREG_SET_ORDER, 0);
echo $matches[0][1]."<br>";
/*RECHERCHE DE L'OUTIL AYANT Generé PDF*/
$re = '/Producer \((.*)\)/m';
preg_match_all($re, $pdf, $matches, PREG_SET_ORDER, 0);
echo $matches[0][1]."<br>";
/*Recherche du nombre de pages dans le pdf*/
$re = '/Count (.*)/m';
preg_match($re, $pdf, $matches, PREG_OFFSET_CAPTURE, 0);
echo $matches[0][1]."<br>";
/*Compter le nombre d'images dans le pdf*/
$re = '/Subtype \/Image/m';
preg_match_all($re, $pdf, $matches, PREG_OFFSET_CAPTURE, 0);
echo "Il y a ".(count($matches[0]))." images dans ce pdf";
/*Ce pdef a t il un mot de passe ?*/
$re = '/\/Encrypt(.*)/m';
preg_match_all($re, $pdf, $matches, PREG_OFFSET_CAPTURE, 0);
if (count($matches[0])>0)
{
echo "<br>Ce fichier est protégé par un mot de passe<br>";
}
else
{
echo "<br>Ce fichier n'est pas protégé par un mot de passe<br>";
}
$re = '/Encoding(.*)/';
preg_match($re, $pdf, $matches, PREG_OFFSET_CAPTURE, 0);
echo $matches[1][0]."<br>";
/* Maintenant extraire chacune des données et faire une belle présentation*/
?>