
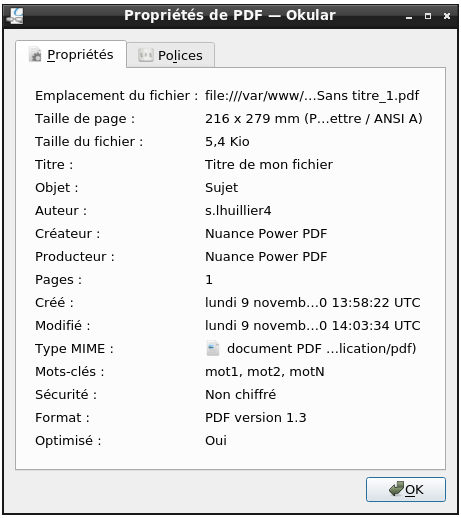
Aujourd'hui je vais vous présenter un besoin que j'ai eu dans un cadre professionnel. Je dois récupérer des métadonnées de fichiers, tous au format PDF, afin de les afficher sur la page web sur laquelle ce propre fichier PDF est téléchargeable. Voyons comment je me suis pris pour réaliser cette prouesse.
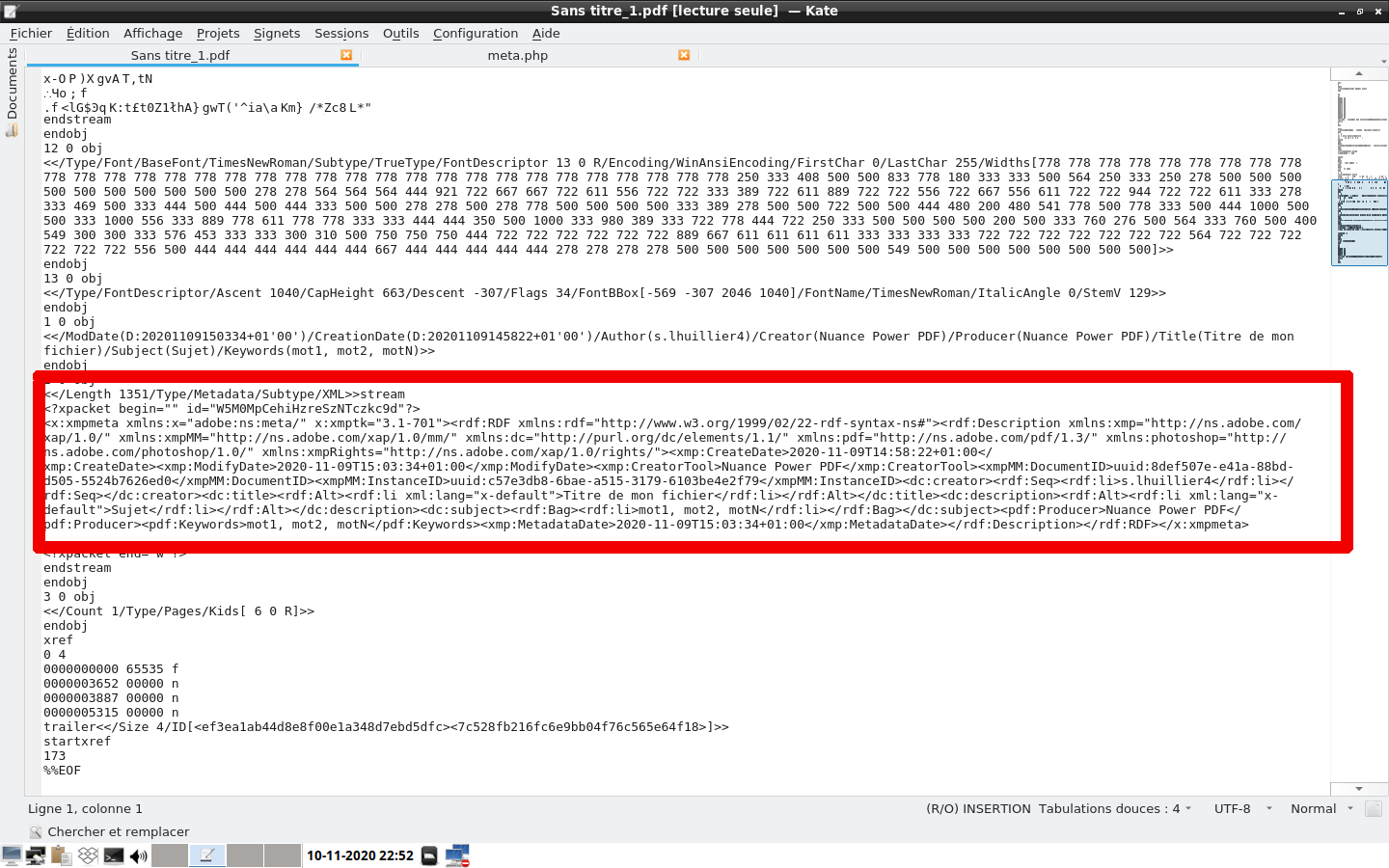
<?PHP $lines = file('Sans titre_1.pdf');
function everythingintags($string, $tagname) { $pattern = "#<\s?$tagname\b[^>]>(.?)</$tagname\b[^>]>#s"; preg_match($pattern, $string, $matches); return $matches[1]; }
foreach ($lines as $line_num => $line) {
if (strpos($line, "xmpmeta") !== false ) {$a=$line; }
}
function extractString($string, $start, $end) { $string = " ".$string; $ini = strpos($string, $start); if ($ini == 0) return ""; $ini += strlen($start); $len = strpos($string, $end, $ini) - $ini; return substr($string, $ini, $len);}
$string = filegetcontents('Sans titre_1.pdf');echo '<div style="width:900px;height:180px;border:2px solid black;box-shadow: 20px 20px 20px lightgreen;font-size:70%;">';echo '<div style="background-color:yellow;font-weight:bold;width:100%;text-align:center;">Propriétés du fichier</div>';echo '<div style="width:25%;background-color:#ffe8e9;float:left;">Date de modification : </div><div style="background-color:#ffe8e9;width:100%;">'.date("d M Y, H:m:s",strtotime(extractString($string, '<xmp:ModifyDate>', '</xmp:ModifyDate>')))."</div>";echo '<div style="width:25%;background-color: #e7f9dd;float:left;">Date de création : </div><div style="background-color: #e7f9dd;width:100%;">'.date("d M Y, H:m:s",strtotime(extractString($string, '<xmp:CreateDate>', '</xmp:CreateDate>')))."</div>";echo '<div style="width:25%;background-color:#ffe8e9;float:left;">Générateur du PDF : </div><div style="background-color:#ffe8e9;width:100%;">'.extractString($string, '<xmp:CreatorTool>', '</xmp:CreatorTool>')."</div>";echo '<div style="width:25%;background-color: #e7f9dd;float:left;">Identifiant du PDF : </div><div style="background-color: #e7f9dd;width:100%;">'.extractString($string, '<xmpMM:DocumentID>', '</xmpMM:DocumentID>')."</div>";echo '<div style="width:25%;background-color:#ffe8e9;float:left;">ID de l\'instance du PDF : </div><div style="background-color:#ffe8e9;width:100%;">'.extractString($string, '<xmpMM:InstanceID>', '</xmpMM:InstanceID>')."</div>";echo '<div style="width:25%;background-color: #e7f9dd;float:left;">ID de l\'auteur du PDF : </div><div style="background-color: #e7f9dd;width:100%;">'.extractString($string, '<rdf:li>', '</rdf:li>')."</div>";echo '<div style="width:25%;background-color:#ffe8e9;float:left;">Titre du PDF :</div><div style="background-color:#ffe8e9;width:100%;">'.extractString($string, '<rdf:li xml:lang="x-default">', '</rdf:li>')."</div>";echo '<div style="width:25%;background-color: #e7f9dd;float:left;">Sujet du PDF : </div><div style="background-color: #e7f9dd;width:100%;">'.extractString($string, '<rdf:Alt><rdf:li xml:lang="x-default">', '</rdf:li></rdf:Alt>')."</div>";echo '<div style="width:25%;background-color:#ffe8e9;float:left;">Mots cles du PDF : </div><div style="width:100%;background-color:#ffe8e9;">'.extractString($string, '<rdf:Bag><rdf:li>', '</rdf:li></rdf:Bag>')."</div>";
echo '<div style="width:25%;background-color: #e7f9dd;float:left;">Producteur du PDF : </div><div style="background-color: #e7f9dd;width:100%;">'.extractString($string, '<pdf:Producer>', '</pdf:Producer>')."</div>";
echo '<div style="width:25%;background-color:#ffe8e9;float:left;">Date d\'écriture des métadata du PDF : </div><div style="width:100%;background-color:#ffe8e9;">'.date("d M Y, H:m:s",strtotime(extractString($string, '<xmp:MetadataDate>', '</xmp:MetadataDate>')))."</div>";echo "</div>";?>